
We firmly believe that high-quality annotation is crucial for the success of AI projects. Quality annotation, or quality labeling, not only enhances the overall performance but also contributes to time and cost savings.
To ensure top-notch quality, we People for AI approach it from three different levels:
- Labelers’ Continuous Training
- Workflows to Evaluate the Correctness of Labeled Data
- Quality Assessment Process
Labelers’ Continuous Training
Training labelers lays the foundation for the successful execution of annotation projects. As labelers need to continually improve throughout production, we employ techniques to facilitate their onboarding and accelerate their learning process. Training is an agile and ongoing process, not a static endeavor. Labelers continue to learn and receive training “on the job” during production, utilizing various methods and resources.
Here at People for AI, we ensure continuous training of our teams through five methods.
Train
Formal initial training is a prerequisite in every project. It occurs before the production phase and is based on labeling instructions provided by the client, which labelers can refer to. The duration of this training depends on the complexity of the tasks to be performed.
Ask
In each project, we implement a Q&A procedure, encouraging our labelers to submit questions through a designated Q&A file. These questions are addressed first, by senior labelers; second, by managers; and if necessary, by the client, in cases where internal answers are unavailable. This approach is crucial for exploring undocumented details and nuances in data labeling instructions. By maintaining a comprehensive Q&A file, we effectively track all questions and answers, facilitating the clarification of data labeling instructions. This streamlined process enables faster and clearer training when scaling the labeling output, if needed.
Interact with clients
An effective way for our teams to make rapid progress is through direct interaction between our local project managers and the client (a weekly meeting can be scheduled, for instance). Live explanations save time for both labelers and clients, especially when dealing with complex cases. This interactive approach fosters a sense of connection, enabling smooth collaboration and communication.
Interact with other team members
Given that members of our teams share the same workspace, they work closely together, supporting each other under the guidance of our team leaders. The team leaders also provide feedback based on validation workflows (like review, for instance) and daily metrics.
Maintain stable teams
Maintaining stable teams is prioritized to retain knowledge and minimize the need for retraining, whenever possible. At People for AI, we provide good working conditions, including health, retirement and training benefits, fostering a healthy atmosphere within our offices. As a result, our turnover rate is remarkably low, enabling us to preserve knowledge and minimize the need for retraining.
“PFAI is a competent partner for annotation services and has supported us in several projects of different kinds. The processes are very lean and flexible, while the project team always keeps close communication with us. The team provides consistent high quality annotations for complex tasks and have proven a strong Q&A and review process.”
Sid Hinrichs, Head of Strategy at Pointly
Workflows to Evaluate the Correctness of Labeled Data
A second level in maintaining high-quality data labeling is selecting the appropriate workflow to evaluate the correctness of the labeled data. These workflows are established during the project’s initial stages, tailored to the task complexity. Clients have the flexibility to select from various options, deciding whether to apply to samples or the entire production dataset.
Typically, four workflows can be used to evaluate the correctness of the labeled data.
- Without validation
- Review
- Consensus voting
- Honeypot (or ground-truth)
Without validation
In this approach, there is no additional validation of the label other than the annotator’s own assessment. Each piece of data is annotated by a single, well-trained annotator.
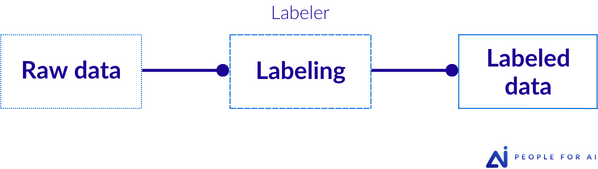
Review
This workflow is commonly chosen for its cost-effectiveness. After the initial labeling, a review and correction phase takes place, providing valuable feedback. In this case, each piece of data is annotated by a single annotator, and a reviewer will review part or the entire previously labeled dataset.

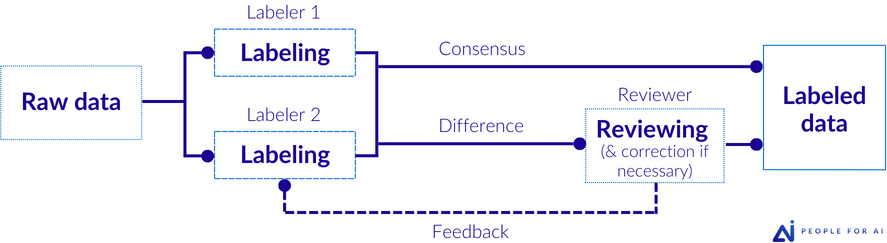
Consensus voting
This involves labeling the same piece of data multiple times and validating the data only if all annotators agree on the label. In this case, each piece of data is annotated by at least two annotators, with a potential round of review in case of disagreement.
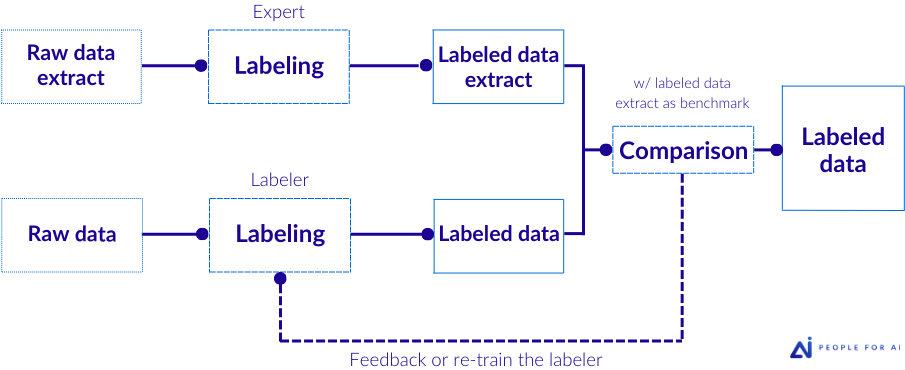
Honeypot (or ground truth)
At the beginning of the project, an expert (often the client) accurately labels an extract of the data. This extract, called “the honeypot”, is then used as a benchmark to assess the quality of subsequent labels provided by annotators. In this case, each piece of data is annotated by a single annotator, with the addition of an expert labeler at the project’s outset.
It’s worth noting that the workflow doesn’t need to remain static throughout the entire project. For projects involving reviewing, an approach that entails 100% reviewing would be excessively costly. Instead, an adaptive workflow proves effective, wherein a robust review process is implemented at the project’s outset. As labelers improve their performance through feedback from reviews, the proportion of reviewing in the workflow gradually decreases. The same principle applies to consensus voting, which is typically applied to only a fraction of the labels, eg. 10%.
Then, agility plays a crucial role in this process, allowing for responsive adjustments and refinements, which will favorably affect the cost, the speed and the quality of the labeled output.
Quality Assessment Process
As previously mentioned, in data labeling projects, ensuring the quality of annotations is of foremost importance. However, the process of assessing quality can be resource-intensive, both for clients and the workforce. In most data labeling projects, the use of complex metrics is rare due to their time-consuming computation.
While straightforward metrics may be sufficient for some projects, they may not be suitable for all projects, especially when quality is hard to reach or of pinnacle importance. As a result, striking the right balance between efficiency and accurate quality assessment becomes crucial to optimize the data labeling process.
With this in mind, let’s explore three balanced approaches to assess quality annotation: subject assessment, accuracy and geometric precision.
SUBJECTIVE ASSESSMENT
One approach is the subjective assessment, where clients and/or experts evaluate (review) the labeled data and judge if it looks satisfactory without formal computation.
ACCURACY
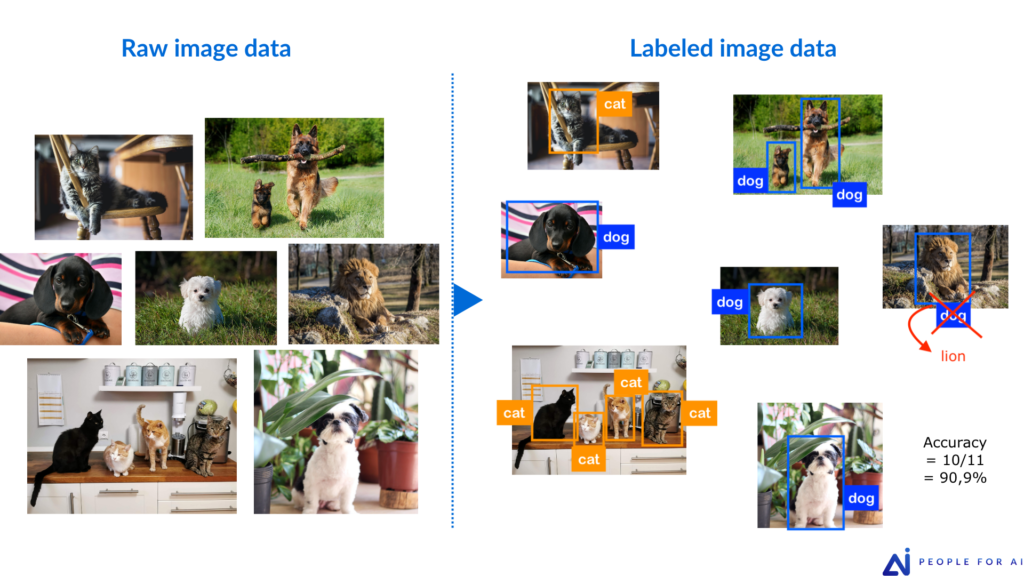
Another simple metric is accuracy, which measures the ratio of correctly labeled data to the total labels. Essentially, it involves counting the number of well-labeled data points out of the total observed and then compute the percentage of well-labeled data. Accuracy can be computed on a per-image/video/piece-of-data basis or on a per-annotation basis.
Accuracy relates to the correctness or reliability of the annotations and focuses on reducing false positives and false negatives. It encompasses errors of presence/absence (e.g., the presence/absence of a Bbox or segmentation) and classification (e.g., the correct identification of an object or a class).
Using accuracy as a metric is common in the review process, where the percentage of labels considered accurate is evaluated by clients, experts, or senior annotators. For instance, if a sample of data is reviewed and 96% of the labels are deemed correct, we can conclude that the sampled data achieved 96% accuracy.
However, one point to consider is that this assessment process will lead to additional efforts as clients may need to label some sample data themselves for evaluation.
GEOMETRIC PRECISION
One more valuable, yet more specific and resource-intensive, metric is geometric precision. It refers to the level of geometric exactness or detail required in the annotations.
High precision demands more detailed and meticulous annotations, which can increase the time passed per labeled data point. It often involves measurements like how closely a bounding box should enclose an object’s sides or how accurately key points should be placed in an image.
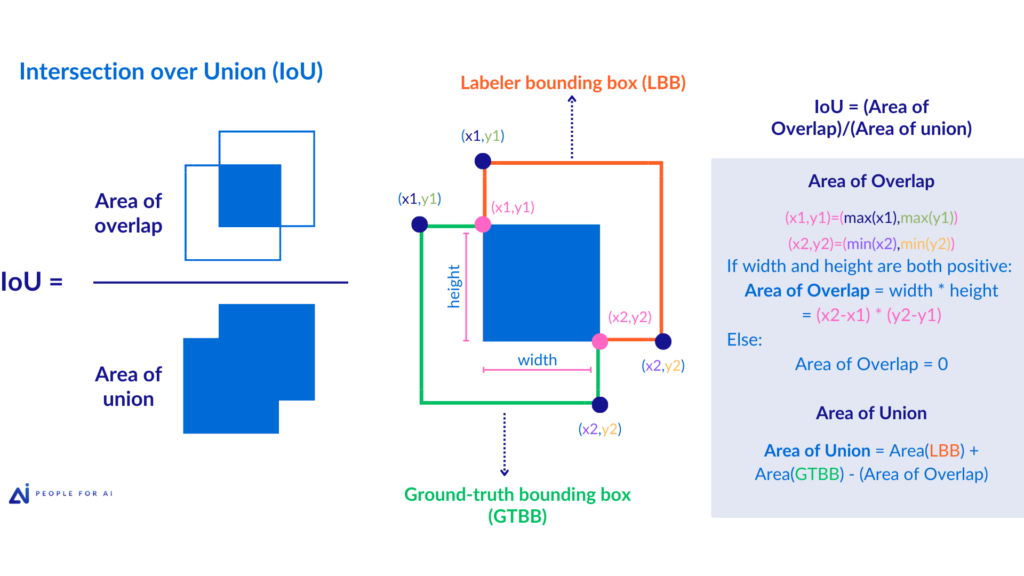
An example of a precision metric is Intersection over Union (IoU), which can be used on bounding box annotations. The IoU value is used to measure the precision of the bounding box around an object without being overly restrictive. First, an expert has to label a ground truth (its bounding boxes will be considered having a precision of 100%), then computing the IoU value, it will assess how closely the bounding boxes from other annotators align with this ideal representation.
Client’s role
Metrics and thresholds to monitor and ensure annotation quality can be established by the client based on the project’s specific needs. While validation workflows and continuous learning are important, they can only be monitored thanks to quality KPIs. Client inputs and requirements hold paramount importance in defining these criteria.
The involvement of the client from the project’s inception is key. It ensures alignment with quality objectives, fostering a collaborative approach to achieve optimal results in data labeling endeavors.
This was particularly evident during the Foodvisor project, where some challenges necessitated the use of complex metrics for a period. However, as trust between partners grew and understanding deepened, we found that simpler metrics sufficed, leading to the discontinuation of complex computations.
People for AI’s role
It’s important to note that, in order to reach quality metrics, annotators should be a part of a collaborative team. This team and its surroundings may ensure constant monitoring and management of the objectives set by the client.
Moreover, depending on the project’s needs, internal assessments on these metrics may be implemented on a frequent basis, which enables us to proactively anticipate potential issues and provide timely feedback to our labelers. This feedback loop fosters a continuous improvement cycle, empowering our labelers to enhance their skills and deliver increasingly reliable annotations.
Conclusion
By adopting these three approaches – Labelers’ Continuous Training, Workflows to Evaluate Correctness and Quality Assessment Processes – we, as People for AI, maintain a strong focus on delivering quality annotation, ensuring the success of AI projects while maximizing efficiency and achieving cost savings. However, achieving above-average quality requires more than just focus on quality metrics; it demands support from the entire organization. Enabling labelers to ask questions without facing pressure, retaining skilled labelers through competitive remuneration and benefits, and preserving knowledge are crucial aspects that reinforce our commitment to providing exceptional annotation services.


