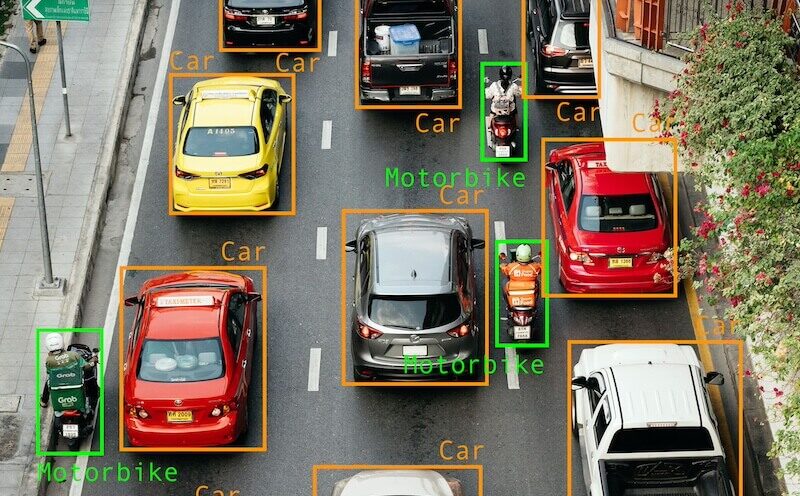
Une boîte englobante (bounding box) est un contour rectangulaire dessiné autour d’un objet ou d’une région d’intérêt dans une image. Cette technique est couramment utilisée pour annoter des images dans le cadre de projets d’apprentissage automatique. Elle est principalement utilisée dans le domaine de la Vision par ordinateur (Computer Vision) pour des tâches telles que la détection d’objets et la classification d’images.
Les bounding boxes représentent une des façons les plus rapides et les plus communes d’annoter des objets.
Pour sa création, l’annotateur dessine un rectangle autour de l’objet/région d’intérêt dans l’image, en utilisant un outil d’annotation des données. Ensuite, nous la définissons généralement à l’aide de deux ensembles de coordonnées x et y.
Les boîtes englobantes peuvent annoter une large variété d’objets ou de régions dans les images, tels que:
- des personnes,
- des animaux,
- des bâtiments,
- des véhicules,
- et bien d’autres!
En français, on utilise souvent le mot anglais bounding box. Les traductions possibles peuvent être :
- boîte englobante
- boîte limite
- rectangle limite (voire rectangle à limite minimum)
D’autres types d’annotations (ou d’étiquettes) sont souvent associées à ces boîtes englobantes pour fournir des informations supplémentaires sur les objets ou les régions représentés. Deux exemples d’annotations différentes sont les classes (pour identifier un objet, comme « pomme », « poire », « orange ») et les attributs (pour ajouter des détails spécifiques à l’objet, comme le niveau de maturité, l’occlusion, etc.)
Enfin, il est parfois intéressant de faire pivoter les boîtes englobantes pour mieux encadrer certains objets qui sont tournés. Il s’agit d’une fonctionnalité de certains outils d’annotation appelée “oriented bounding box” ou « boîte englobante orientée ».
Synonyms: Bounding Box; Bbox; BB